
Introduction
In this article, we go through the fundamental concepts that make up Apache Kafka. We use a real stream of events named EventStreams provided by Wikipedia by sending them to a Kafka topic.
This tutorial aims to provide familiarization with Apache Kafka, a Python client library to interact with Kafka and also serve as a playground for further experimentation. This setup is meant to run on a local system; security and scalability issues are not taken into account, the configurations used are minimal.
Apache Kafka
Apache Kafka is probably the most famous publish/subscribe messaging system, and there are very good reasons for its excessive adoption from various industries. Over the past few years, it has gained more popularity due to the increasing demand for real-time data exploitation (analysis, processing, visualization).
Many e-books and articles have been written explaining what Apache Kafka is and how it works. In this article, I will try to make a short overview of the most important points that you need to be introduced to and give you some reference for additional information. I have highlighted the most important keywords.
The Ecosystem
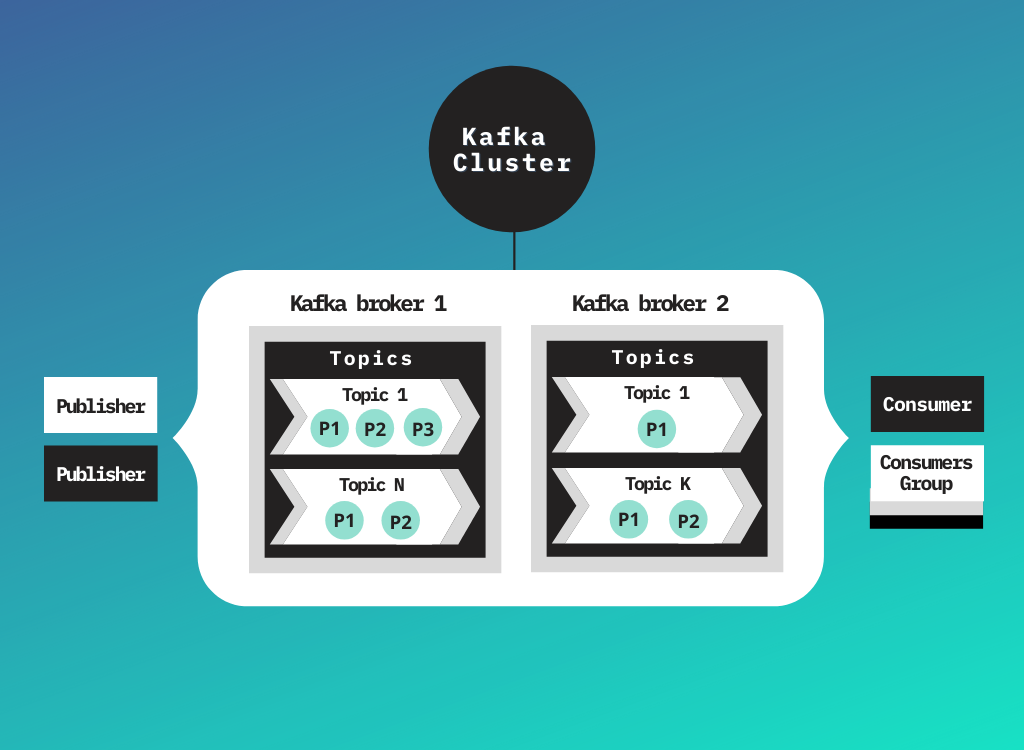
The unit of data within Kafka is called message. A message is simply an array of bytes, which can also contain a bit of metadata called key, which is also a byte array. Depending on the use case, keys may be used or not. They provide a way to populate topics’ partitions in a more controlled manner. A message can also be referred to as a key-value pair; you can think of them as records in a traditional SQL database.
In most cases, messages need to have some structure that can easily be interpreted from other systems (schema). The most popular formats being used are JSON, XML and Avro.
In Kafka ecosystem, messages are being produced in batches to minimize overhead due to the round trip of a message inside the network.
Messages are categorized into different topics to separate them based on some attribute. Topics can also be divided into partitions, which provides extra scalability and performance, as they can be hosted into different servers. You can think of topics as an append-only log, which can only be read from beginning to end. In the SQL world, topics would be our tables.
There are two types of clients; publishers and consumers. As their names imply, publishers send messages to topics, and consumers read them.
A Kafka node is called a broker. Brokers are responsible for acquiring messages from producers, storing them in the disk and responding to consumers requests. Many brokers form a cluster. Partitions can only be owned by one broker into a cluster called the leader.
Key features
Some of the key features that make Apache Kafka excel:
- Multiple producers can publish messages at the same time on the same topics.
- Multiple consumers can read data independently from others or in a group of consumers sharing a stream and ensuring that each message will be read-only once across a group.
- Retention data published to the cluster can persist in disk according to given rules.
- Scalability, Kafka is designed to be fully scalable as it is a distributed system that runs on multiple clusters of brokers across different geographical regions, supporting multiple publishers and consumers.
- Performance, on top of the features mentioned above, Kafka is extremely fast even with a heavy load of data, providing sub-second latency from publishing a message until it is available for consumption.
In this tutorial, we will set up a Kafka cluster with a single node as a proof of concept. In production environment scenarios to leverage Kafka's full potential, it is suggested to set up a cluster of multiple nodes (at least three). This will be the foundation to achieve replication of data across nodes in order to build a fault-tolerant system.
If you want to dive deeper into the Kafka ecosystem, I suggest reading Kafka The Definitive Guide, among other e-books that you can find for free on the official website of Kafka. This book will provide all the low-level knowledge that you need to understand how Kafka works, but also guidelines and suggestions to deploy in a production environment.
kafka-python
This project uses the kafka-python library to publish events to a Kafka topic due to its simplicity in use. Of course, there are alternatives like Confluent’s official library or pykafka that you can use instead of kafka-python.
There are of course many client libraries that you can also use from different programming languages. Client libraries written in Java and Scala can be considered more suitable for a production environment, as speaking to Kafka’s native language will provide more options when it is required to accomplish more complex tasks. Also, those libraries are more mature than the ones written in Python.
EventStreams
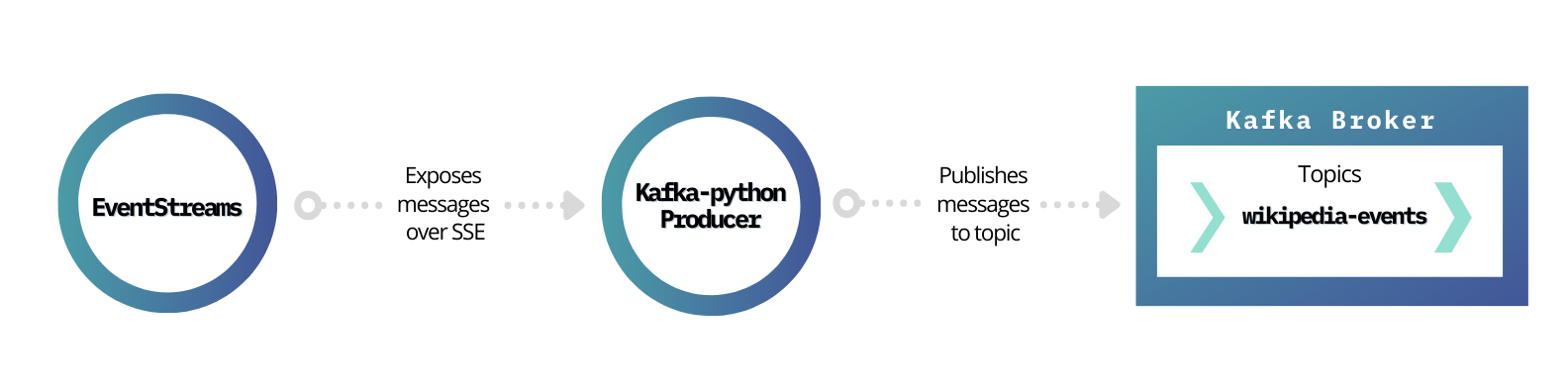
As mentioned in the introduction, EventStreams is a web service that exposes a continuous stream of events over HTTP, using chunked transfer encoding, following the Server-Sent Events (SSE) protocol. Those events are related to Wikipedia’s users’ actions that alter the state of existing Wikipedia web pages (editing and categorization) and also to the addition of new ones (web pages).
In this project we are only interested in events related to the edit of existing web pages,, so we filter events coming from the EventsStreams service accordingly. Edit events contain information like date of editing, editor’s user name, a flag value (depending on if it was a bot or human that made the edit/change), title of article and much more metadata. For the sake of this tutorial, we choose to only keep some of these variables to publish to Kafka; however, you can create your own message schema depending on the use case you want to simulate.
Edit events come with different namespaces that identify different type of article categories. Those namespaces are integers when consumed from EventStreams, ,but we map them to their id name according to this table.
An example of the final JSON schema of our messages is the following:
{
"id": 1426354584,
"domain": "www.wikidata.org",
"namespace": "main namespace",
"title": "articles_title",
"timestamp": "2021-03-14T21:55:14Z",
"user_name": "a_user_name",
"user_type": "human",
"old_length": 6019,
"new_length": 8687
}
Set up project
Start Kafka Broker locally
Open a new terminal to fire up the Zookeeper cluster manager. By default port 2181 will be used in a machine:
bin/zookeeper-server-start.sh config/zookeeper.properties
In a second terminal, start a single Kafka broker locally. By default, it will run at port 9092.
bin/kafka-server-start.sh config/server.properties
Open a third terminal in order to interact with Kafka. Start by listing the currently available topics in your local host broker.
bin/kafka-topics.sh --list --zookeeper localhost:2181
Create a new Kafka topic, naming it wikipedia-events. In this topic, we will propagate (publish) all the edit events coming from EventStreams service.
Variables replication-factor and partitions are optional. The first one refers to the number of different nodes that this topic should be initialized, this option helps you achieve fault tolerance mentioned before and only makes sense in a cluster with multiple brokers. Partitions also provide scalability across multiple brokers; a value other than 1 (one) doesn’t really make sense in this case.
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wikipedia-events
Listing once again our topics, Wikipedia-events should be printed out in the console.
Set up a Python environment
Start by cloning the GitHub project to your local machine.
git clone https://github.com/ZisisFl/kafka-wikipedia-data-stream.git
When cloning is complete, navigate to the project folder.
First, we need to create a new Python 3 virtual environment (this is not mandatory but highly recommended). We name this environment kafka_env. All the required libraries for this project are included in the requirements.txt file. In case you want to install the essential libraries on your own, be careful to use pip install kafka-python instead of pip install kafka (following commands probably won’t apply to a Windows OS).
python3 -m venv kafka_venv
source kafka_venv/bin/activate
pip install -r requirements.txt
Execute the Python script “wikipedia_events_kafka_producer.py” and open up a new terminal to consume messages from the kafka topic through a terminal, using the following command. Option from-beginning is not required; when used, it will provide the whole history of messages that have been published to the target topic; otherwise, you will consume messages from the moment you execute the following command and beyond.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wikipedia-events --from-beginning
Multiple JSON objects should be printed out in the console!
Suggestions for experimentation
- Create multiple producers that handle different types of events and send them over different or the same topics.
- Create consumer(s) that will store data to a database into batches or feed them to any other system.
- Create a group of consumers that will share the job of consuming messages in parallel to improve performance.